Linear Regression
A regression is a method to calculate the relationships between a dependent variable (Y) and independent variables (Xi). When using this model, you should validate the following: Regression validation
Simple Linear Regression (Go to the calculator)
You may use the linear regression when having a linear relationship between the dependent variable (X) and the independent variable (Y). When adding one unit to X then Y will be changed by a constant value, the b1 coefficient.
H0: Y = b0
H1: Y = b0 + b1X
Regression calculation
The least squares method is used to calculate the coefficients b and a. This approach chooses the line that will minimize the sum of the square length of the real values (Y) from the linear line (ŷ).
$$Min(\sum_{i=1 }^{n}(\hat y_i-y_i)^2)$$ $$b_1=\frac{\sum_{1}^{n}(x_i-\bar{x})(y_i-\bar{y}) }{\sum_{1}^{n}(x_i-\bar{x})^2}\\ b_0=\bar{y}-b_1\bar{x}$$ R2 is the ratio of the variance explained by X with the total variance (Y)
R is the correlation between X and Y
$$R=a*\frac{var(x)}{var(y)}$$
Multiple Linear Regression (Go to the calculator)
When having more than one dependent variable, the multiple regression will compare the following hypothesis, using the F statistic:
H0: Y = b0
H1: Y = b0+b1X1+...+bpXp
Choosing the independent variables is an interactive process. You should check each coefficient for the following hypothesis:
H0: bi = 0
H1: bi ≠ 0
Each time you should remove only the one most insignificant variable (p-value > α) changing the "include" sign from √ to χ
After removing one insignificant variable, other insignificant variables may become significant in the new model.
Assumptions
- Linearity - a linear relationship between the dependent variable, Y and the independent variables, Xi
- Residual normality - the tool will run the Shapiro-Wilk test per each variable, but for the regression model, the only required normality assumption is for the residuals.
- Homoscedasticity, homogeneity of variance - the variance of the residuals is constant and does not depend on the independent variables Xi
- Variables - The dependent variable, Y, should be continuous variable while the independent variables, Xi, should be continuous variables or ordinal variables (ordinal example: low, medium, high)
- No Perfect Correlation (Multicollinearity) - between two or more independent variables, Xi.
- Independent observations
Overfitting
It is tempting to increase the number of independent variables to increase the model fitting, but you should beware that any additional independent variable may increase the fitting of the current data but will not improve the prediction of future data.Cannot calculate the model
The tool will not be able to calculate the model when having one of the following problems. Technically it would not be able to calculate the inverse of the following matrix multiplication: XtX- Too many independent variables (Xi) or too small sample size.
Solution: Reduce the number of independent variables or increase the sample size. - Multicollinearity, two independent variables (Xi) has a perfect correlation (1).
Solution: Remove one of the variables.
White test
Test for homoscedasticity, homogeneity of variance using the following hypothesis
$$ H_0: \hat\varepsilon_i^2=b_0\\ H_1: \hat\varepsilon_i^2=b_0+b_1\hat Y_i+b_2\hat Y_i^2 $$ While the ε is the residual and Ŷ is the predicated Y, the test will run a second regression with the following variables:
Independent variable: Y' = ε2.
Dependent variables: X'1=Ŷ, X'2=Ŷ 2.
The tool uses the F statistic which is the result of the second regression. Another option is to use the following statistic: χ2=nR'2 while n is the sample size and R'2 is the result of the second regression.
- Try to transform the dependent variables Xi, square root for count variable, log for skew variable and other
- You may be missing an independent variable or combination (xi or xixj or xi2)
- Weighted regression
Regression calculation
Calculate the regression's parameters without matrices is very complex, but it is very easy with the matrix calculation.
p - number of independent variables.
n - sample size.
Y - dependent variable vector (n x 1). $$\hat Y (predicted \space Y) \space vector (n x 1).$$ X - independent matrix (n x p+1). Ε - Residuals vector (n x 1). B - Coefficient vector (p+1 x 1) $$Y=\begin{bmatrix} &Y_1\\ &Y_2\\ & :\\ &Y_n \end{bmatrix} \hat Y=\begin{bmatrix} & \hat Y_1\\ & \hat Y_2\\ & :\\ & \hat Y_n \end{bmatrix} X=\begin{bmatrix} &1 &X_{11} &X_{12} & .. &X_{1p} \\ &1 &X_{21} &X_{22} & .. &X_{2p} \\ & : & : & : & : & : \\ &1 &X_{n1} &X_{n2} & .. &X_{np} \end{bmatrix}\\ Ε=\begin{bmatrix} & \varepsilon_1\\ & \varepsilon_2\\ & :\\ & \varepsilon_n \end{bmatrix} B=\begin{bmatrix} &b_0\\ &b_1\\ &b_2\\ & :\\ &b_p \end{bmatrix}\\$$ Y = XB + Ε, is equivalent to the following equation: Y = b0 + b1X1 + b2X2+...+bpXp+ε
$$ B = (X'X)^{-1}X'Y\\ \hat Y=XB\\ Ε=Y-\hat Y$$ Calculate the Sum of Squares, Degrees of Freedom and the Mean Squares
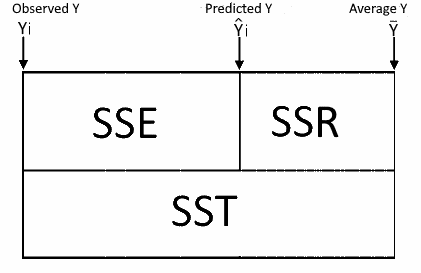
Coefficients Confident Interval $$Lower=B_i+SE_i+t_{\alpha/2}(DFE)\\ Upper=B_i+SE_i+t_{1-\alpha/2}(DFE)\\ $$
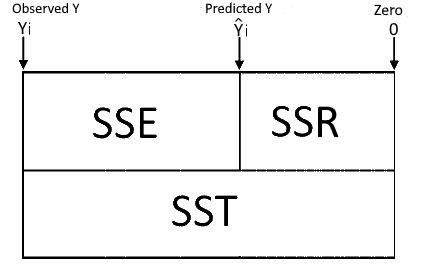
Regression model without an intercept (without constant)
You use this model when you are sure that the line must go through the origin.
Usually it is not recommended to use the model without the intercept! especially when the data used doesn't include values near the origin, in this case the model may be linear around the observations, but not linear near the origin
The X Matrix doesn't include the first column of 1.
$$ X=\begin{bmatrix} &X_{11} &X_{12} & .. &X_{1p} \\ &X_{21} &X_{22} & .. &X_{2p} \\ & : & : & : & : \\ &X_{n1} &X_{n2} & .. &X_{np} \end{bmatrix}\\ B=\begin{bmatrix} &b_1\\ &b_2\\ & :\\ &b_p \end{bmatrix}\\$$ Y = XB + Ε, is equivalent to the following equation: Y = b1X1 + b2X2+...+bpXp+ε
In the model without the intercept, the SST and the SSR are related to zero instead of Y average (y̅). Therefore you can't compare the R-squared of the model with the constant to the R-squared of the model without the constant. Since the SST calculation isn't related to the average, there is no need to reduce one degree of freedom. So DFT = n.
Hence DFE = DFT - DFR = n - p.
Numeric Example
Data
| X1 | X2 | Y |
|---|---|---|
| 1 | 1 | 2.1 |
| 2 | 2 | 3.9 |
| 3 | 3 | 6.3 |
| 4 | 1 | 4.95 |
| 5 | 2 | 7.1 |
| 6 | 3 | 8.5 |
Following the data as a matrix structure.
| SS | DF | MS | |
|---|---|---|---|
| Total (T) | 26.359375 | 2 | 13.179688 |
| Residual (E) | 0.259375 | 3 | 0.0864583 |
| Regression (R) | 26.618750 | 5 | 5.323750 |
R2 = 0.990256
Adjusted R2 = 0.983760
F = 152.439759 $$ Covariance(B)=MSE(X'X)^{-1}=\begin{bmatrix} & \textbf{0.1153} & -0.0096 & -0.0336\\ & -0.0096 & \textbf{0.0064} & -0.0064\\ & -0.0336 & -0.0064 & \textbf{0.0280} \end{bmatrix} \\ \space\\ Var(B)=diagonal(Covariance(B))=\begin{bmatrix} &\textbf{0.1153}\\ &\textbf{0.0064}\\ &\textbf{1.0280} \end{bmatrix} \\ \space\\ SE(B)=Sqrt(Var(B))=\begin{bmatrix} &\textbf{0.3395}\\ &\textbf{0.0800}\\ &\textbf{0.1674} \end{bmatrix} \\ \space\\ T_i=\frac{B_i}{SE_i}(DFE)\\ \space\\ DFE=3\\ \space\\ T=\begin{bmatrix} &0.6627\\ &11.4545\\ &6.0986 \end{bmatrix} \quad $$ For example: 0.2250/0.3395 = 0.6627