分布计算器
计算值之间的概率或百分位数或概率. EnglishMessage
信息
该工具计算以下分布的累积分布(p)或百分位(𝑥₁): 正态分布,二项式分布,T分布,F分布,卡方分布, 泊松分布,威布尔分布,指数分布.选择 𝑥1 计算基于百分比的累积概率, 要么 p(X≤𝑥1) 根据累积概率计算百分位数 要么 𝑥1, 𝑥2 计算 p(𝑥1≤X≤𝑥2)
概率密度函数(PDF)
对于连续分布,密度是累积分布函数的导数。例如,钟形曲线表示正态分布的密度。
特定X范围的密度下的面积(该范围的整数)是在该范围内获得值的概率。 p(X =𝑥)= 0.
概率质量函数(PMF)
对于离散概率分布,值density的密度是获得该值的概率:p(X =𝑥)。正态分布
正态分布(也称为高斯分布)是在统计分析中使用最广泛的。这通常是因为许多自然过程是自然分布的或具有非常相似的传播。
正态分布数据的一些示例包括身高,体重和测量误差。
正态分布具有对称的“贝尔曲线”结构。 中心附近存在更多数据,这是平均值,值越远离中心,发生的可能性就越小。
通常,当添加独立随机变量时,结果趋向于正态分布(CLT-中心极限定理)
您可以基于标准正态分布(均值等于零且标准差等于1的正态分布)计算任何正态分布的值。
当X正常分布时, μ 是平均值, σ 是标准偏差, Z=(x - μ)/σ 分布为标准正态分布,因此您可以基于标准正态分布计算任何正态分布。
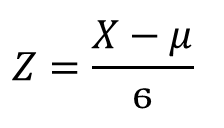
二项式分布
二项式分布是离散分布,用于计算在实验中获得特定成功次数的概率 进行n次试验,成功概率为p。在计算百分位数时,通常没有X能够满足您输入的确切概率。 该工具将计算X,该X将生成等于或大于输入概率的分布 但会计算X和X-1的概率。
当工具无法使用二项式分布来计算分布或密度时, 由于样本量大和/或获得了大量成功,它将使用法线近似 μ = np 和 σ=√(np(1-p)), 或为进行百分位数计算,可能的话可能是使用二项式分布的两个分布的组合。
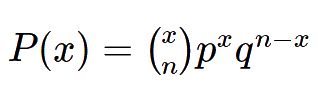
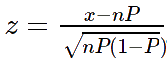
T分布
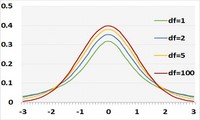
T型学生分布是用于正态分布总体的人为分布, 当我们不知道总体的标准偏差或样本量太小时。T分布看起来与正态分布相似,但中间位置较低,尾部较粗。 形状取决于自由度,独立观察数,通常是观察数减一(n-1)。 自由度越高,它越类似于正态分布。
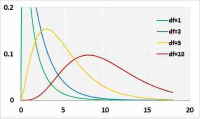
卡方分布
卡方分布用于正态分布总体,是独立平方标准正态随机变量的累积。令Z1,Z2,.... Zn为独立的标准随机变量。
令X = [Z1 ^ 2 + Z2 ^ 2 + .... + Zn ^ 2]。
X分布为具有n个自由度的卡方随机变量。
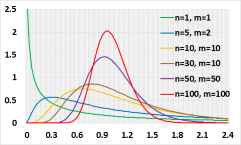
F分布
F(Fisher Snedecor)分布用于正态分布的种群。 作为独立平方标准正态随机变量的除法累加或两个卡方变量之间的除法。设Z 1 ,Z 2 ,.... Z n 是独立的标准随机变量。
令X 1 = [Z 1 2 + Z 2 2 +。 .. + Z n 2 ]。
令Z' 1 ,Z' 2 ,.... Z' n 是独立的标准随机变量。
令X 2 = [Z' 1 2 + Z' 2 2 + .... + Z' m 2 ]。
令X =(X 1 / n)/(x 2 / m)。
X分配为 F 随机变量,其自由度为 n (分子),自由度为 m (分母)
X 1 作为具有 n 自由度的卡方随机变量分布。
X 2 分布为自由度为 m 的卡方随机变量。
使用示例:方差分析(ANOVA)测试,用于比较方差的F测试。
泊松分布
泊松分布是离散分布,描述了获得固定时间单位的事件数的概率。所有事件都是独立的。λ是每单位时间的平均事件数。
t 时间单位上的事件数将Poisson分布为 tλ 平均事件数。
事件之间的时间分布指数,均值等于1 / λ。
指数分布
指数分布是泊松分布的互补分布,它表示事件之间时间的分布。分布的唯一特征是无记忆-从现在到下一个事件的时间分布与您已经等待的时间无关。
无记忆的例子:如果在接下来的2个月内灯泡烧坏的可能性为0.3,而您等待了1年却没有任何事件, 现在,未来2个月内发生事件的可能性仍然为0.3。
例: 如果事件是灯泡故障,并且一个月内需要更换的平均灯泡数量为16。
5个月内需要更换的灯泡数量为Pois(80)。 由于:5 * 16 =80。
有故障的灯之间的时间间隔为Exp(1/16)。 单位是月。
威布尔分布
威布尔分布是一种连续分布,用于可靠性作为生命周期分布。当k = 1(形状)时,故障率是恒定的。 这是指数分布。
当k> 1(形状)时,故障率会随着时间增加。